Understanding principal component analysis
In this post, we’ll take a deep dive into PCA, from both a mathematical and implementation perspective. We’ll derive the equation from the ground up, look at how we can compute it and finally end with what it can be used for. This post is primarily targeted at those with a basic understanding of PCA but want to know the assumptions it relies on, its properties and derive how it can be computed.
If you’re interested in the repository containing the Jupyter notebook from which this is derived, it’s here.
The optimal coding perspective
Finding a low dimensional representation
PCA can be thought of as finding a low-dimensional representation of a set of vectors. Given points in an n-dimensional space, we might wish to find some new k-dimensional space (with k < n) which captures as much of the essence of the original space as possible. The exact definition of capturing the ‘essence’ is subject to design, however, we can consider it from multiple perspectives.

The notion of reconstruction error
If we take our low-dimensional representation and attempt to recover the original n-dimensional vector of each point, we could measure how much each point varies from its reconstruction. The difference between each reconstruction and the original, is one way of measuring the effectiveness of our new k-dimensional space and is the approach taken by PCA. Naturally, this requires a definition of a similarity between two matrices. If we have a matrix $X$ of our original points and our reconstruction $X'$ then we can define the difference between them as a sum of the square of errors $\sum_{i,j} (X-X')_{i,j}^2$.
This quantity is known as the Frobenius norm of the matrix $||X-X'||_F$ and is essentially an extension of the L2 ($||\mathbf{v}||_2^2 = \sum_i \mathbf{v}_i^2 = \mathbf{v}^\top \mathbf{v}$) norm from vectors to matrices. It is just a fancy name for squaring every element in a matrix and taking their sum. Crucially, however, we can see that the Frobenius norm of a matrix, $A$, is precisely equivalent to $Tr[A^\top A]$ (see the illustration below).

As a result, our error of interest, can be computed as $Tr[(X-X')^\top (X-X')]$, this will come in handy since the trace operator comes with a bunch of neat tricks for manipulating the matrices involved.
PCA Assumptions
We’ve defined how we’re going to evaluate this reconstruction, but not at all the means of performing the coding or its inverse.
PCA chooses to implement both the encoding and decoding as a matrix multiplication. So we can think of PCA as finding a matrix $D$ that will transform our input, $X$ to our coded version $C$ by a matrix multiplication (i.e. $C = XD$). The matrix, $X$, being our original data of $m$ rows and $n$ columns.
We might choose, however, to use some matrix, $D_k$ which reduces the number of dimensions of our data from $m$ to $k$. To make it easier, we can tag the matrix with the new number of dimensions. If this is the case, then $D_k$ is of size $n \times k$ and so that the resulting coding, $C$, is of size $m \times k$.
One of the most crucial assumptions made by PCA is that the transformation matrix, $D_k$, has orthonormal columns. Criticially, this does not, technically, make it an orthogonal matrix since it may not be square and the rows may not be orthonormal.
This assumption is useful since it simplifies the reconstruction process, in fact, $X'$ can be computed as $XD_kD_k^\top$, i.e. we can use the transpose of the encoding matrix to perform the decoding.
To understand exactly why the reconstruction can be performed by the transpose of the matrix let’s consider a code $\mathbf{z}$ which we’ve generated as $\mathbf{z}=\mathbf{D}\mathbf{x}$ and are decoding using $\mathbf{D}^\top$.
The reconstruction error is $(\mathbf{x}-\mathbf{D}^\top\mathbf{z})^\top(\mathbf{x}-\mathbf{D}^\top\mathbf{z}) = \mathbf{x}^\top\mathbf{x} - \mathbf{x}^\top\mathbf{D}^\top\mathbf{z}-\mathbf{z}^\top\mathbf{D}\mathbf{x} + \mathbf{z}^\top\mathbf{D}\mathbf{D}^\top\mathbf{z}$.
We can take the derivative with respect to the code $\mathbf{z}$, $\nabla_\mathbf{z} = -2\mathbf{D}\mathbf{x} + 2\mathbf{D}\mathbf{D}^\top\mathbf{z}$, which given the definition of $\mathbf{z}$ is equal to $-2\mathbf{D}\mathbf{x} + 2\mathbf{D}\mathbf{D}^\top\mathbf{D}\mathbf{x}$.
We defined our matrix to have orthonormal columns so we know that $\mathbf{D}^\top\mathbf{D} = \mathbf{I}$ because the dot product of each column with itself will be one. Hence, our gradient is $-2\mathbf{D}\mathbf{x} + 2\mathbf{D}\mathbf{I}\mathbf{x} = \mathbf{0}$. This tells us that our encoding/decoding system is at a stationary point in the reconstruction error. Note that this only tells us for an individual point that was encoded with a matrix that has orthonormal columns, decoding with the transpose is a good idea. It doesn’t tell us anything about how to pick $\mathbf{D}$ or what happens if you use it for multiple points.
Given these assumptions, we can reframe our problem as finding the coding matrix which minimises the reconstruction error.
This means that formally, for some given value $k$, we wish to discover the matrix $D_k^*$.
$$D_k^* = argmin_{D_k} ||X-X'||_F = argmin_{D_k} ||X-XD_kD_k^\top||_F$$
Discovering the coding function
Given that we wish to minimise the reconstruction error, let us attempt to discover the transformation precisely capable of this.
We’ll need a few tricks to get us there.
- $(A+B)^\top = A^\top + B^\top$
- $(AB)^\top = B^\top A^\top$
- $(A^\top)^\top = A$
From the visual illustration, recall that we can write the reconstruction error as $\text{Tr}((X-XD_kD_k^\top)^\top(X-XD_kD_k^\top))$.
By using the rules this can be expanded into $$\text{argmin}_{D_k}\text{Tr}(X^\top X -X^\top XD_kD_k^\top - D_kD_k^\top X^\top X + D_kD_k^\top X^\top XD_kD_k^\top)$$
We are, however, only interested in the effect of the matrix $D_k$ so we’ll axe the first term $$\text{argmin}_{D_k}\text{Tr}(-X^\top XD_kD_k^\top - D_kD_k^\top X^\top X + D_kD_k^\top X^\top XD_kD_k^\top)$$
Crucially, however, the trace operator has two useful properties for us:
- it’s insensitive to cyclic permutations (i.e. $\text{Tr}(ABC) = \text{Tr}(CAB) = \text{Tr}(BCA)$)
- the trace of a sum of matrices is the sum of their traces (i.e $\text{Tr}(\sum_i \mathbf{A}_i) = \sum_i \text{Tr}(\mathbf{A}_i)$)
Given this, we can write the equation of interest as: $$\text{argmin}_{D_k}-2\text{Tr}(-X^\top XD_kD_k^\top)+ \text{Tr}(D_kD_k^\top X^\top XD_kD_k^\top)$$.
Furthermore, since we define the columns of $D_k$ as being orthonormal, $\mathbf{D}_k^\top \mathbf{D}_k = \mathbf{I}$ and so we can rewrite the second term as $\text{Tr}(\mathbf{D}_k^\top \mathbf{X}^\top \mathbf{X}\mathbf{D}_k)$ which matches the form of the first term (from permuting it) and therefore can be written as the following maximisation.
$$\text{argmax}_{\mathbf{D}_k} \text{Tr}(\mathbf{D}_k^\top \mathbf{X}^\top \mathbf{X}\mathbf{D}_k)$$
This is sets up exactly the quantity that PCA is attempting to maximise.
Relationship with eigendecomposition
Having happily derived the maximisation problem, I’ll do my best to convince you that this is, in fact, maximised by having the k-columns of $\mathbf{D}_k$ as the k eigenvectors of $\mathbf{X}^\top\mathbf{X}$ with largest eigenvalues. This will roughly take the form of an inductive proof. So let’s start with considering $k=1$, that is if we had the choice of using a single vector, what would we go with?
Base case
We’ll use the lowercase, $\mathbf{d}$, to emphasise that it’s a vector rather than matrix. So let’s try and tackle:
$$\text{argmax}_{\mathbf{d}} \text{Tr}(\mathbf{d}^\top \mathbf{X}^\top \mathbf{X}\mathbf{d})$$
The trace of a scalar, is defined as itself, so we wish to find $$\text{argmax}_{\mathbf{d}} \mathbf{d}^\top \mathbf{X}^\top \mathbf{X}\mathbf{d}$$
However, recall that we mandated as our first assumption that the columns of $\mathbf{D}$ are orthonormal and hence we know that $\mathbf{d}^\top\mathbf{d} = 1$.
This allows us to reframe this as a constrained optimisation problem and use Lagrange multipliers to discover which vector minimises the quantity of interest whilst satisfying the norm constraint. For convenience, we’ll use $\mathbf{A} = \mathbf{X}^\top \mathbf{X}$.
Hence we can write this as: $$L(\mathbf{d}, \mathbf{A}, \lambda) = \mathbf{d}^\top \mathbf{A}\mathbf{d} - \lambda(\mathbf{d}^\top \mathbf{d} - 1)$$
TL;DR Lagrange multipliers are just a technique for optimising a function over a specific region, in our case we’re not looking for all vectors but only ones with a norm of 1. We rewrite the function to include the constraint and take the derivative of the new function, known as the Lagrangian.
By taking the derivative of $L$ we can find the solution.
$$\frac{\partial L}{\partial \mathbf{d}} = 2\mathbf{A}\mathbf{d} - 2\lambda\mathbf{d}$$
The derivative is precisely zero when $\mathbf{A}\mathbf{d} = \lambda\mathbf{d}$, that is when $\mathbf{d}$ is an eigenvector of the matrix $\mathbf{A}$. Furthermore, we can see that the quantity in fact takes on the associated eigenvalue since $\mathbf{d}^\top \mathbf{A}\mathbf{d} = \mathbf{d}^\top \lambda\mathbf{d} = \lambda $, where $\lambda$ is the associated eigenvalue. This is always possible since we can mandate that the eigenvector has a unit norm.
Hence, we can see here that for the base case, the best vector is the eigenvector with the largest eigenvalue.
Inductive step
Having showcased our hypothesis for $k=1$, let’s see what happens for other values of $k$. Precisely, let us show that if our hypothesis is true for some arbitrary $k$ then it is also true for some $k+1$. That is the best encoding matrix with $k+1$ columns, consists of the $k+1$ unit eigenvectors with the largest associated eigenvalues.
We are now interested in the following problem.
$$\text{argmax}_{\mathbf{D}_{k+1}} \text{Tr}(\mathbf{D}_{k+1}^\top \mathbf{X}^\top \mathbf{X}\mathbf{D}_{k+1})$$
The key insight comes from thinking of the $\mathbf{D}_{k+1}$ as the previous matrix,$\mathbf{D}_{k}$, for which we have assumed the property to hold, and a new column which we would like to show corresponds the eigenvector with the $(k+1)$-th largest eigenvalue.

The matrix of interest is split into two new matrices, $\Lambda_k$ and $\Lambda_{k+1}$ as shown in the diagram. So we can rewrite the maximisation and expand it.
$$\text{argmax}_{\mathbf{\Lambda}_{k+1}} \mathrm{Tr}((\mathbf{\Lambda}_{k} + \mathbf{\Lambda}_{k+1})^\top \mathbf{X}^\top \mathbf{X}(\mathbf{\Lambda}_k + \mathbf{\Lambda}_{k+1}))$$
$$\text{argmax}_{\mathbf{\Lambda}_{k+1}} \mathrm{Tr}[\mathbf{\Lambda}_{k}^\top \mathbf{X}^\top \mathbf{X}\mathbf{\Lambda}_{k} + \mathbf{\Lambda}_{k+1}^\top \mathbf{X}^\top \mathbf{X}\mathbf{\Lambda}_{k} + \mathbf{\Lambda}_{k}^\top \mathbf{X}^\top \mathbf{X}\mathbf{\Lambda}_{k+1} + \mathbf{\Lambda}_{k+1}^\top \mathbf{X}^\top \mathbf{X}\mathbf{\Lambda}_{k+1}]$$
We’ll slowly get rid of three of these four terms and show our initial hypothesis holds.
- First term: is a constant from our perspective and so we don’t have to consider it
- Second and third term: I’ll try to convince you from the diagram that both of these have zero entries along the diagonal. The diagram shows why it’s true for the second term and by symmetry we can see it’s also true for the third term. Since they have zeroes along the diagonal they will have a trace of zero and hence by splitting the trace we end up with $\mathrm{Tr}[\mathbf{\Lambda}_{k+1}^\top \mathbf{X}^\top \mathbf{X}\mathbf{\Lambda}_{k+1}]$ as the final maximisation.

However, if we look carefully enough we can see that the fourth term has zeroes everywhere other than in the bottom right corner, which I denote by $\mu$.

Furthermore, from the diagram we can see that $\mu = \mathbf{a}'\mathbf{d}_{k+1}$ and that $\mathbf{a}'=\mathbf{d}_{k+1}^\top\mathbf{A}$.
Now we can, finally, reframe our inductive case as $$\text{argmax}_{\mathbf{d}_{k+1}} \mathbf{d}_{k+1}^\top\mathbf{X}^\top\mathbf{X}\mathbf{d}_{k+1}$$
However, recall that we mandated that all the columns of the encoding matrix are orthonormal and hence, this condition is maximised, precisely, by the eigenvector with (k+1)-th largest eigenvalue. It is important to note that the eigenvectors (corresponding to different eigenvalues) are orthogonal here, since $\mathbf{X}^\top \mathbf{X}$ is real and symmetric. Given that we chose our base case as an eigenvector, we know that if we pick the $k+1$ vector as a different eigenvector, it will necessarily be orthogonal to all the other columns.
Finally, this induction cannot continue indefinitely, since we cannot have $n+1$ orthogonal $n$-dimensional vectors. This is intuitive since PCA is designed to find a lower-dimensional representation not increase the number of dimensions. I hope I have convinced you that the we can find the principal components by eigendecomposition of $\mathbf{X}^\top \mathbf{X}$.
That is, if we write it as $\mathbf{X}^\top \mathbf{X} = \mathbf{V}\text{diag}(\mathbf{\lambda})\mathbf{V}$, with the matrix $V$ containing the eigenvectors as columns and with eigenvalues in the vector $\mathbf{\lambda}$ then we can pick our encoding matrix as the $k$ eigenvectors with largest eigenvalues.
Relationship with SVD
Recall that singular value decomposition is defined as rewriting a matrix, $\mathbf{A}$, as a product, $\mathbf{U}\mathbf{D}\mathbf{V}^\top$, of orthogonal matrices, $\mathbf{U}$ and $\mathbf{V}$ and a diagonal matrix $\mathbf{D}$.
Crucially, however, $\mathbf{V}$ is defined as the eigenvectors of the matrix $\mathbf{A}^\top\mathbf{A}$. Sound familiar? That’s precisely the eigenvectors that we need for the PCA encoding.
Hence, we know that if $\mathbf{X}^\top \mathbf{X} = \mathbf{V}\text{diag}(\mathbf{\lambda})\mathbf{V}$, then we could also write $\mathbf{X} = \mathbf{U}\mathbf{D}\mathbf{V}^\top$, where $\mathbf{V}$ is our encoding matrix.
This now leaves us with two separate but equivalent ways of computing our encoding matrix — SVD or eigendecomposition.
The decorrelation perspective
There are two key properties of PCA to understand:
- Minimisation of the reconstruction error
- ‘Decorrelation’ of the features of data
We’ve just finished showing the first one so let’s take a quick look at the second (much easier to show!).
Recall the unbiased estimator of the covariance of a centered matrix, $\mathbf{Z}$, is $\text{Var}[\mathbf{Z}] = \frac{1}{m-1}\mathbf{Z}^\top\mathbf{Z}$ where $m$ is the number of rows of the matrix. The covariance matrix is such that $\text{Var}(\mathbf{Z})_{i,j} = \text{cov}(\mathbf{Z}_i, \mathbf{Z}_j)$, that is it tells us the covariance between random variables.
If we can show that the covariance of PCA-encoded data, $\mathbf{Z}$ is a diagonal matrix, then we will know that covariance between each feature derived by PCA is zero. We know that $\mathbf{Z} = \mathbf{X}\mathbf{D}$, if $\mathbf{X}$ is our original data and $\mathbf{D}$ is the encoding matrix.
Therefore $\text{Var}[\mathbf{Z}] = \frac{1}{m-1}\mathbf{Z}^\top\mathbf{Z} = \frac{1}{m-1}\mathbf{D}^\top\mathbf{X}^\top\mathbf{X}\mathbf{D}$.
However, recall that from the SVD approach we know that $\mathbf{X} = \mathbf{U}\mathbf{\Sigma}\mathbf{D}^\top$ for a diagonal matrix $\mathbf{\Sigma}$.
From this we can rewrite $\mathbf{X}^\top\mathbf{X}$ as $(\mathbf{U}\mathbf{\Sigma}\mathbf{D}^\top)^\top(\mathbf{U}\mathbf{\Sigma}\mathbf{D}^\top)=\mathbf{D}\mathbf{\Sigma}^\top\mathbf{U}^\top\mathbf{U}\mathbf{\Sigma}\mathbf{D}^\top$, but since SVD gives us orthogonal matrices we know that $\mathbf{U}^\top\mathbf{U}=I$. Hence, $\mathbf{X}^\top\mathbf{X} = \mathbf{D}\mathbf{\Sigma}^\top\mathbf{\Sigma}\mathbf{D}^\top$
At this point, we’re very close and you might be tempted to suggest that $\mathbf{\Sigma}^\top\mathbf{\Sigma} = \mathbf{\Sigma}^2$ since $\mathbf{\Sigma}$ is a diagonal matrix, and the transpose of a square, diagonal matrix is itself. However, $\mathbf{\Sigma}$ is not necessarily square! In fact, from the properties of SVD it has the same dimensions as $\mathbf{X}$. We do, however, know that the matrix $\mathbf{\Sigma}^\top\mathbf{\Sigma}$ is necessarily diagonal since it is a product of two diagonal matrices, and so the point still stands.
Hence, we have shown that the resulting encoding has a diagonal covariance matrix, which means that the features have no linear dependence between each other. We’ll be able to visualise this later!
It’s crucial to understand that a zero covariance does not imply that no relationship exists between the features of the transformed space but rather that no linear relationship can exist. The stronger condition of having no relationship, would require a different algorithm and is the approach taken by Independent Component Analysis.
One of the beauties of PCA is that there are lots of ways to think about it. I’ve only presented one, but you can also think about it as maximising variance, or transforming the coordinate axes amongst many others.
Implementation
I didn’t say much about what PCA can be used for, but now that we have an understanding of where the computation comes from, let’s take a quick look at what it can be used for. We’ll look at it as a technique for compression and for visualisation of high-dimensional data.
We can implement it in two-lines both via eigendecomposition and SVD. Although, we are essentially cheating since NumPy is doing all the heavy-lifting by computing the eigenvectors for us. That being said, computing eigenvectors should be itself the topic of a separate blog post.
The only nuance is that we need to center the matrix. This means that each column is supposed to have a mean of zero. It is rather rare to see a description of why we need to do this, in fact, it will also very frequently work without doing it. However, recall that when we proved that PCA decorrelates data we made the assumption that the data was centered. Without this assumption we wouldn’t have been able to use $\text{Var}[\mathbf{X}] = \frac{1}{m-1}\mathbf{Z}^\top\mathbf{Z}$ as an estimate of the covariance matrix.
|
|
Toy example
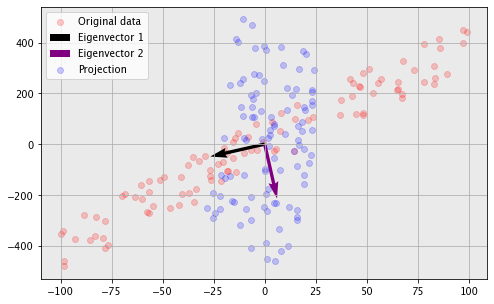
We can generate a noisy straight line and take a look at the effect of PCA on it.
|
|
Notice the direction of the eigenvectors plotted. This points out a property of PCA that was only briefly mentioned — the PCA components are in the directions of maximum variance. PCA is trying to use its first component to capture as much of what distinguishes points as possible. We can also see from the projected version the property of decorrelating data, which we just proved.
|
|
Let’s compare our simple two-line implementations to the sklearn implementation.
|
|
[[ 0.22883214 0.9734659 ]
[ 0.9734659 -0.22883214]]
[[-0.9734659 -0.22883214]
[ 0.22883214 -0.9734659 ]]
[[-0.22883214 -0.9734659 ]
[ 0.9734659 -0.22883214]]
They match (considering that eigenvectors may be arbitrarily multiplied by -1), but I still wouldn’t rely on ours too much! SkLearn is doing a bunch of stuff behind the scenes to make sure it is always accurate!
Country data
Another common use-case of PCA is for visualising high-dimensional data. We can use the earlier derivation to select a matrix which projects our data down into two-dimensions. For example, I’ve taken some 7-dimensional data from Wikipedia on the happiness of populations around the world. If we wished to plot the countries in relation to each other we could use the two eigenvectors with largest eigenvalues (as we showed earlier). This new matrix where each row only consists of two features, can be plotted and understood by mere mortals without the ability to visualise 7-dimensions.
|
|
| Overall rank | Country or region | Score | GDP per capita | Social support | Healthy life expectancy | Freedom to make life choices | Generosity | Perceptions of corruption | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | Finland | 7.769 | 1.340 | 1.587 | 0.986 | 0.596 | 0.153 | 0.393 |
| 1 | 2 | Denmark | 7.600 | 1.383 | 1.573 | 0.996 | 0.592 | 0.252 | 0.410 |
| 2 | 3 | Norway | 7.554 | 1.488 | 1.582 | 1.028 | 0.603 | 0.271 | 0.341 |
| 3 | 4 | Iceland | 7.494 | 1.380 | 1.624 | 1.026 | 0.591 | 0.354 | 0.118 |
| 4 | 5 | Netherlands | 7.488 | 1.396 | 1.522 | 0.999 | 0.557 | 0.322 | 0.298 |
Let’s take the numeric columns (and exclude the score) which we will pass to the PCA algorithm. Given this, we take the two first columns of the returned eigenvector matrix (it’s returned sorted by eigenvalue so this is ok!) and project down by taking the matrix multiplication with the encoding matrix.
|
|
[0 1 2 3 4 5 6 7]
We can now plot the projected version as a two-dimensional plot. Try zooming in and out to see how ‘similar’ countries tend to clump together in the resulting plot. Hover your mouse over a point to see additional information about the country. We’ve managed to preserve a lot of the information of the original 7 dimensions.
Eigenfaces
A common recent application of PCA is the so-called ‘eigenfaces’. That is, if we apply PCA to a dataset of images of faces we can attempt to generate a compact code for faces. For example, suppose we use 100x100 face images, this means that we effectively have a 10000-dimensional space in which all faces must exist. Obviously this is rather unwieldy and so, say, if we could generate say a code of 400 real numbers for a face, it could be useful for compressive purposes or indeed for face recognition.
Eigenfaces specifically refers to the projection vectors which applying PCA to faces generates. These essentially represent the directions of most variance in our original 10000-dimensional space and help to point out some interesting things that PCA is doing.
To test our implementation out on faces, I used the following Kaggle dataset, which you can download to path in the code to reproduce the notebook.
Interestingly we can take a look at the ‘mean’ (in the sense of average) face in the dataset — pretty generic.

We can use PCA to reduce the number of components of our image data from 2400 to some new reduced number of dimensions. Given this new low-dimensional representation we’ll try to reconstruct the original and take a look at the reconstructed image. As we can see, people frequently become recognisable well before 2400 dimensions. Some people are even recognisable with as little as a few hundred components.
If you rerun the cell, it will pick a person at random from the dataset and show this grid of images again.
|
|

PCA, in some sense, is quite interpretable. We can take a look at exactly what it’s considering, that is, the directions of the eigenvectors it’s using.
In this specific case, we can look at and interpret them as images which each test image is being projected onto.

If you thought that looked weird, let’s look at some of the other components. They get more and more bizarre at a first glance. However, we know that most faces roughly look the same, so later eigenvectors will be distinguishing less and less, hence why they become less obvious.

Thanks for reading I hope it was useful or at least mildly interesting.